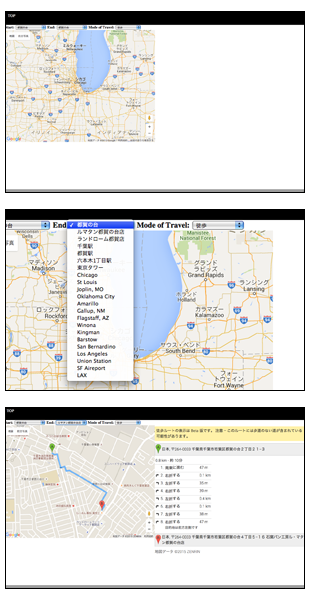
防災をネタにGoogleMapのAPIを勉強している。今回は避難経路マップを作る。HTMLとJavaScriptのプログラミングが必要だが、Googleのサンプルをほぼそのまま使うので、コードを書く必要はほとんどない。
まず、近所の避難場所の情報を集めてくる。
住所があれば良いのだが、小学校名や施設の名前でも検索ができる。
次にGoogleMapAPIのページからサンプルを取ってくる。持っていない人はGoogleAPIのキーも手に入れる必要がある。
このページの最初のサンプルはプルダウンメニューから出発点と目的地を選ぶようになっている。このプルダウンメニューのデータを書き換える。valueに入っている値を避難場所の名前(例えば「○○小学校」)などに変更するだけでよい。このままでは車で移動するルートを検索してしまうので、travelMode: google.maps.TravelMode.DRIVINGをtravelMode: google.maps.TravelMode.WALKINGに書き換える。
本来であればAとBの位置を割り出し、ルートを検索し、受け取ったデータを地図上に解釈するという手続きが必要なのだが、それはすべてAPIがやってくれる。ズーミングも自動で行われる。つまり、何のプログラミングも必要ないのである。
directionsDisplay.setPanel(document.getElementById(“directionsPanel”));という一文を加え、displayエリアのdiv(idをdirectionsPanelとする)を追加すると経路図も表示してくれる。
出発点の住所を入力できるようにしたければ、プルダウンメニューをテキストボックスに書き換えてやればよいだろう。
このプログラムでは最短距離が自動的に検索される。ユーザーが自分で経路を考えたい場合にはdirectionsDisplay = new google.maps.DirectionsRenderer();をdirectionsDisplay = new google.maps.DirectionsRenderer({draggable:true});と書き換える。すると、経路が動かせるようになる。経路を動かすと自動的に所要時間が再計算される。これもAPIでやってくれるので、自分でプログラミングする必要はない。
 持ち運び可能なタブレット端末がある場合には現地のロケーションを使用することも可能。現地ロケーションを探す機能をジオ・ロケーションと呼ぶらしく、情報取得のサンプルはここから入手できる。ここで取得した値を単にstartに代入すればよいだけらしい。つまり文字列が住所なのか施設名なのかそれとも座標なのかはGoogleで勝手に判断してくれるようだ。
持ち運び可能なタブレット端末がある場合には現地のロケーションを使用することも可能。現地ロケーションを探す機能をジオ・ロケーションと呼ぶらしく、情報取得のサンプルはここから入手できる。ここで取得した値を単にstartに代入すればよいだけらしい。つまり文字列が住所なのか施設名なのかそれとも座標なのかはGoogleで勝手に判断してくれるようだ。
今回は避難経路地図を例題にして勉強したのだが、もちろんこの地図は会社案内の道順案内にも応用が聞く。トラベルモードにトランジット(TRANSIT)という選択肢があり、乗り換え案内にも対応しているらしいのだが、アメリカ国内だけの対応らしい。試しに経路検索したところ、ロスアンゼルスからサンフランシスコまでバスで行けという指示になった。その内に日本でも導入されるかもしれない。